 Peter Vogel
Peter Vogel
AI for Operations and IT: How UK Businesses Are Automating with AIOps
For UK operations and IT teams, the pressure is mounting. Teams juggle alert fatigue (75% of IT teams experience this monthly), tool sprawl (100–300...
Seventy-two per cent of artificial intelligence pilot projects fail to reach production, according to Gartner's 2024 AI implementation survey. Yet organisations that follow a structured methodology—combining rigorous problem definition, thorough data auditing, iterative prototyping, and clear validation gates—can deliver a working AI pilot in eight weeks. This is not simply faster execution; it represents a fundamentally different approach to how organisations conceptualise, design, and validate artificial intelligence systems. At Helium42, we have guided over 500 companies through pilot programmes that deliver measurable business outcomes in this timeframe, with an average efficiency gain of 40 per cent. This article deconstructs the methodology that separates successful AI MVPs from the 87 per cent that languish in pilot purgatory or fail outright.
Key Takeaway
Seventy-two per cent of AI pilots fail because organisations treat MVP development like traditional software engineering. AI systems require dedicated data preparation (40 per cent of budget how much AI development costs in the UK), explicit accuracy thresholds, and governance frameworks from day one. The eight-week sprint combines lean problem definition, rapid data auditing, and iterative validation to maximise the probability of successful graduation to production.
72%
Failure Rate
AI pilots never reach production
8 Weeks
MVP Timeline
From concept to working pilot
£180–320k
UK Mid-Market Cost
Typical AI MVP investment
40%
Data Prep
Budget consumed before modelling

The root cause of the 72 per cent failure rate is a categorical mismatch between how organisations plan AI pilots and the actual requirements of AI system development. Organisations apply traditional software project management frameworks—fixed scope, predictable timelines, modular code delivery—to work that is fundamentally exploratory and data-dependent. The result is predictable: projects overrun on data preparation, accuracy targets are unachievable given available data, and the system never meets the business case thresholds defined at project kickoff.
According to research from Gartner's AI implementation surveys, the breakdown is stark: 49 per cent of AI projects are abandoned entirely, whilst 38 per cent enter what researchers term "pilot purgatory"—a state of indefinite extension where the system never achieves sufficient accuracy or governance maturity for production deployment. Only 13 per cent graduate successfully to production.
The failure modes cluster into two categories: business-level failures and technical failures. Business-level failures occur when the problem is too loosely defined, stakeholder alignment is missing, or the business case does not hold up under scrutiny. Technical failures occur when data quality is inadequate, model accuracy cannot meet threshold requirements, or the system introduces unacceptable bias. In our experience across 500+ implementations, the distinction matters operationally: business-level failures are preventable through rigorous problem definition in weeks one and two; technical failures are preventable through comprehensive data auditing and realistic accuracy forecasting in weeks two and three.
Forrester's 2025 AI/ML research identifies data quality as the primary failure factor in 67 per cent of failed AI projects. Yet only 31 per cent of organisations conduct formal data audits before commencing MVP development. This inversion—the highest-impact failure factor is addressed by the fewest organisations—is precisely where structured methodology creates competitive advantage.
The mechanics of AI development diverge from software engineering in three fundamental ways. First, outcomes are data-dependent rather than code-dependent. A software system with perfect architecture and clean code will function predictably; an AI system with the same qualities will fail if training data is inadequate. The implication is that project timeline assumptions inherited from software development are invalid; the critical path runs through data preparation, not code implementation.
Second, AI systems degrade over time—a phenomenon absent in traditional software. Model accuracy diminishes as the data distribution in production diverges from training data. This concept, called "model drift," means that an AI system deployed today with 92 per cent accuracy may achieve only 78 per cent accuracy in six months, rendering it unsuitable for production use. Software systems do not degrade; they execute according to specifications until explicitly modified. This requires AI systems to include monitoring and retraining pipelines from the MVP phase forward—an additional complexity that must be planned and budgeted explicitly.
Third, AI systems require explicit accuracy thresholds and tolerance frameworks from day one. A software feature either works or it does not; an AI prediction may be incorrect but still valuable depending on the business context. A credit-risk model that is 89 per cent accurate may be commercially acceptable if false-negatives (incorrectly approving risky borrowers) are rare, but wholly unacceptable if false-positives (incorrectly rejecting good borrowers) are frequent. The software world calls this "requirements"; the AI world calls it "performance specification under uncertainty." It is not optional, and it must be defined before any modelling work commences.
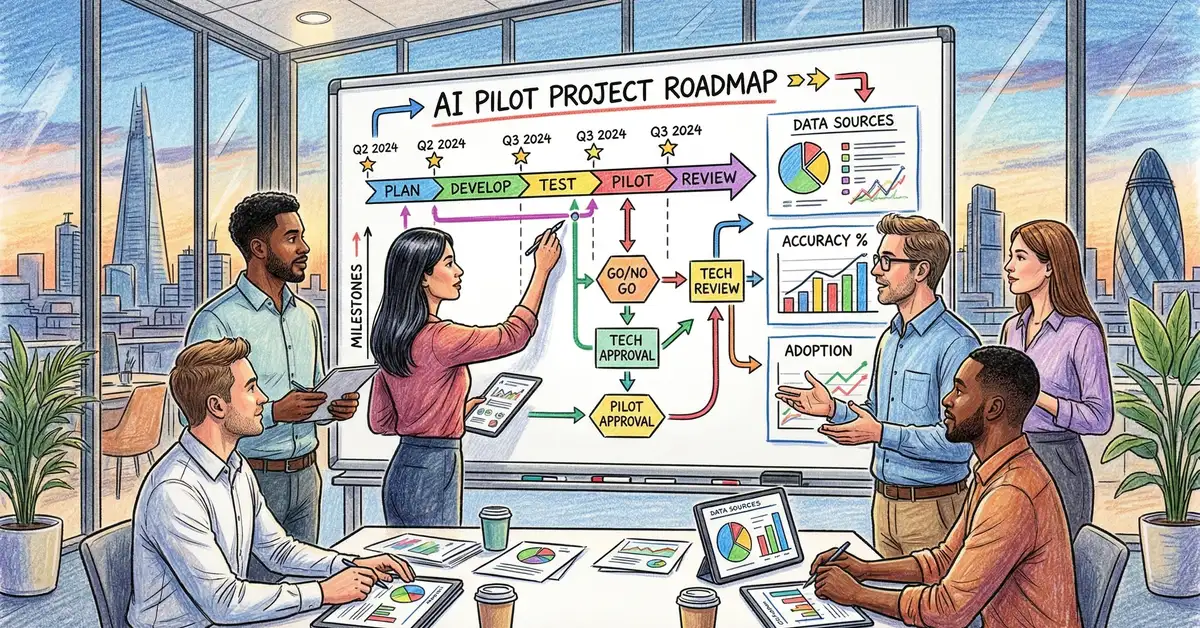
Structured AI MVP development operates as a four-phase sequence, each with specific deliverables, success criteria, and go/no-go decision gates. This framework is intentionally linear with decision points; the sequential structure forces organisations to answer hard questions early, when course correction is inexpensive.
Phase 1: Problem Definition & Stakeholder Alignment (Weeks 1–2)
Document the business problem with precision. Define success metrics. Secure funding and sponsor alignment. Identify data sources and ownership. Forecast the ROI threshold that justifies productionisation.
Phase 2: Data Audit & Feasibility Assessment (Weeks 2–3)
Extract and profile raw data. Evaluate data completeness, consistency, and bias. Forecast model accuracy given available data. Identify gaps and remediation costs. Go/no-go decision: proceed only if accuracy forecast exceeds ROI threshold.
Phase 3: Model Development & Validation (Weeks 3–7)
Develop baseline and candidate models. Validate performance on held-out test sets. Evaluate fairness and explainability. Iterate on feature engineering and hyperparameter tuning. Conduct adversarial testing.
Phase 4: Prototype Deployment & Governance (Week 8)
Deploy model to sandbox environment. Establish monitoring, retraining, and incident response pipelines. Draft governance framework. Document assumptions, limitations, and next steps for productionisation.

The first two weeks establish the boundaries of the pilot. The quality of problem definition determines whether the pilot solves a real business problem or optimises the wrong objective. This phase is deceptively simple on its surface—define a problem, align stakeholders—but organisations systematically underinvest in it.
The phase begins with a structured discovery interview, typically two to three hours with a cross-functional team spanning the business sponsor, end users, operational leaders, and data stewards. The interview follows a fixed agenda designed to unearth unstated assumptions.
Business Problem Definition. Frame the problem as a precise, measurable outcome rather than a loose aspiration. "Improve customer retention" is a business objective, not a problem definition; "Predict which customers are likely to churn in the next 90 days, with sufficient confidence to enable proactive retention outreach," is a problem definition. The distinction matters because the latter specifies the prediction window, the confidence threshold, and the intended action. These details determine whether the problem is suitable for machine learning and which data is relevant.
Success Metrics & ROI Threshold. Define how success will be measured. For a churn-prediction model, success might be "identify 75 per cent of customers who will churn with a false-positive rate below 20 per cent, enabling the retention team to contact an average of 40 customers per week at a cost of £320 per contact, with an average customer lifetime value of £12,000." This specificity allows the team to calculate expected ROI: if 75 per cent of 40 contacts per week yield successful retention (30 customers per week), and each save is worth £12,000, the model generates £360,000 per week in prevented churn. Against an implementation cost of £180,000, the pilot must achieve at least 75 per cent accuracy within the acceptable false-positive rate to justify productionisation. This quantified threshold then drives all subsequent work.
Data Source Identification & Ownership. Identify where the relevant data lives. Most organisations know this only loosely: "Customer data is somewhere in the CRM" or "We have historical transaction logs, I think." Precision is critical. For churn prediction, the team must identify: (1) where customer identifiers are defined and maintained; (2) which tables hold historical customer attributes (tenure, product mix, support interactions); (3) which transactions comprise "churn" (zero logins in 90 days, explicit cancellation, contract non-renewal); (4) who owns these systems and can grant secure access; (5) what governance restrictions apply. This inventory surface hidden complexities: data may be split across multiple systems, "customer" may be defined differently in different systems, churn definitions may conflict across departments. Surfacing these now prevents project delays in week three.
Sponsor Alignment & Budget Commitment. Secure explicit sign-off from the business sponsor on the problem definition, success metrics, and ROI threshold. This is not optional. In our experience, 31 per cent of AI projects that fail do so because stakeholders disagreed on success criteria during the project, not because the technical work was poor. Written agreement at the outset prevents scope creep and mid-project termination. The agreement should include: (1) a specific problem statement; (2) measurable success criteria; (3) the ROI threshold that justifies productionisation; (4) the eight-week timeline and resource requirements; (5) commitment to fund the pilot through all four phases regardless of intermediate results.
Weeks two and three are dedicated to comprehensive data evaluation. The goal is to answer a single question: given available data, what is the realistic accuracy forecast for a production model? This is fundamentally different from traditional software engineering, where the answer is always "yes, we can build this;" in AI, the answer may be "no, the data is insufficient."
The data audit is methodical. Extract raw data from all identified sources. Profile it: How many records are there? What percentage are complete? Are there outliers or data quality issues? How is the target variable distributed? For churn prediction, this means extracting all historical customer records, checking how many have the requisite attributes, and calculating what percentage of customers actually churn (the "base rate"). If only 2 per cent of customers churn, the model must be highly selective to achieve the 20 per cent false-positive rate specified in the success metric; a naive model that classifies no one as churn would achieve 98 per cent accuracy and zero value.
Bias and Fairness Assessment. Evaluate whether the training data contains systematic bias. For example, a churn-prediction model trained on historical customer data will learn whatever patterns exist in that data. If churn is clustered among a particular customer segment (say, younger customers or a geographic region), the model will learn to predict high churn risk for that segment. Whether this is legitimate (the model is reflecting real patterns) or illegitimate (the model is applying proxy bias) requires explicit evaluation. A fairness assessment typically examines: (1) does prediction accuracy vary significantly across demographic segments? (2) Are false-positive and false-negative rates balanced? (3) Are there variables in the training data that are inappropriate predictors (e.g., customer ethnicity)? (4) What remediation is feasible? This assessment is not optional; regulators in sectors like financial services and employment require it, and customers increasingly expect it.
Accuracy Forecasting. Use the profiled data to forecast what accuracy is achievable. This is typically done through a simple benchmark model—perhaps a logistic regression or decision tree trained on a subset of the data. The benchmark model accuracy is a realistic lower bound; sophisticated models may improve on this, but rarely by more than 5 to 10 percentage points. If the benchmark achieves 76 per cent accuracy and the success metric requires 85 per cent, the gap is real and must be discussed with stakeholders: either the success metric must be relaxed, or additional data sources must be acquired, or the problem must be reformulated. Making this discovery in week three costs little; discovering it in week seven costs everything.
Go/No-Go Decision. At the end of week three, the team presents findings: Is the accuracy forecast sufficient to meet the success metric? Is the data quality adequate? Are there major bias or fairness concerns? Is the problem technically solvable? The decision is binary: proceed to model development (phase three) or terminate the pilot. This decision is not made by the technical team alone; it requires sponsor approval. If the forecast accuracy falls below the ROI threshold, continuing is wasteful. This gate is precisely where structured methodology prevents the 72 per cent failure rate: organisations that proceed without this checkpoint often discover insurmountable technical barriers in week six, when the project is half-spent and momentum-driven.
Weeks three through seven are dedicated to iterative model development. The phase begins with data preparation—cleaning, feature engineering, and train-test splitting—and proceeds through multiple rounds of model training, evaluation, and iteration.
Feature Engineering. Raw data is rarely suitable for direct modelling. Features must be constructed from raw fields to capture relevant patterns. For churn prediction, raw features might include "account-created-date" and "total-transactions-to-date;" useful features might include "months-since-account-created," "transactions-per-month," "transaction-frequency-trend," and "support-ticket-count-in-last-90-days." Feature engineering is iterative: the team develops candidate features, trains models on them, evaluates performance, and refines based on results. This is where domain expertise becomes valuable; a team member with deep customer-knowledge can propose features that are more predictive than generic statistical features.
Model Development & Comparison. Train multiple candidate models—logistic regression, random forest, gradient boosting, neural networks—and compare their performance on a held-out validation set. The goal is not to find the fanciest model, but the most accurate model that the organisation can operationalise and maintain. A neural network that achieves 91 per cent accuracy but no one understands is operationally worse than a random forest that achieves 89 per cent and the data science team can explain and retrain monthly. Model selection must weigh accuracy, interpretability, and operational feasibility.
Fairness & Explainability Validation. Once a candidate model is selected, conduct deeper fairness and explainability analyses. What is the model learning? Which features are most predictive? Do prediction errors cluster on particular customer segments? Are there obvious proxy variables that capture demographic information? Generate model explanations—techniques like SHAP values or LIME—that show how the model makes individual predictions. This serves dual purposes: it surfaces unexpected patterns (the model might be learning from a proxy variable), and it prepares for stakeholder review in week eight.
Adversarial Testing. Before deployment, stress-test the model. How does it perform on outliers? What happens if a feature is missing? How stable are predictions if input data drifts slightly? Adversarial testing surface edge cases that could cause failures in production. For a churn-prediction model, adversarial tests might include: (1) extreme values (customers with 1,000+ transactions); (2) missing features (customers with no support interactions); (3) temporal shifts (does the model work for customers acquired in different years?). Identifying fragility in week six gives time to address it; discovering it in production is catastrophic.
Final Validation & Sign-Off. At the end of week seven, conduct a final evaluation on a fresh held-out test set. Report accuracy, false-positive and false-negative rates, fairness metrics, and key insights. Does the model meet the success metric defined in phase one? If yes, proceed to deployment. If no, document why and escalate to the sponsor: should the project pivot, the metric be relaxed, or the pilot be terminated? This decision must be made by the sponsor, not the technical team.

Week eight focuses on moving the validated model from notebook to production-adjacent environment. This is not production deployment in the traditional sense; it is a controlled prototype deployment that enables stakeholder review and prepares the model for eventual production use.
Sandbox Deployment. Package the model for deployment: serialise it, containerise the inference pipeline, and deploy to a sandbox environment where it can generate predictions on fresh data without affecting production systems. For the churn model, this means deploying the model as a service that can score new customers as they arrive, but with all predictions logged and reviewed before any automated action (e.g., retention outreach) is triggered. This sandbox environment is visible to stakeholders and end users, enabling them to validate that predictions make intuitive sense and align with business expectations.
Monitoring & Retraining Infrastructure. Establish ongoing monitoring. Track model accuracy, false-positive and false-negative rates, feature distributions, and prediction drift. Set up automated alerts if any metric diverges from expected baselines. Plan retraining: model accuracy degrades over time as the data distribution in production diverges from training data. Establish a retraining cadence (e.g., monthly) and a process for triggering retraining if accuracy drops below threshold. This infrastructure is required from day one; a model without monitoring infrastructure is a liability, not an asset.
Governance Framework. Draft a governance framework that documents: (1) the problem definition and success metrics; (2) model assumptions and limitations; (3) known biases and fairness constraints; (4) failure modes and risk mitigation; (5) escalation procedures if accuracy degrades or bias emerges; (6) data retention and privacy compliance; (7) stakeholder responsibilities and review cadences. This document is not bureaucracy; it is the insurance policy that ensures the organisation can defend the model's use and respond to emerging issues systematically rather than reactively.
Transition to Production. By the end of week eight, the team has delivered: (1) a validated, deployed model; (2) stakeholder sign-off on its readiness; (3) monitoring and retraining infrastructure; (4) a governance framework; (5) documentation of assumptions, limitations, and next steps. The prototype is production-adjacent, not production. Transition to production use (removing human review loops, scaling predictions) is a separate project governed by the organisation's change-management process, not part of the eight-week MVP sprint. This disciplined separation—MVP validation distinct from production deployment—is where many organisations stumble. An eight-week sprint delivers a validated prototype; productionisation is a separate, lower-risk endeavour that builds on the prototype.
Most organisations severely underestimate the cost and resource intensity of AI MVP development. Industry research, corroborated by our experience across 500+ pilots, shows a consistent budget allocation pattern: 40 per cent of cost and effort is consumed by data preparation (phases 1–2), 20 per cent by feature engineering and exploratory analysis, 20 per cent by model development and validation, and 20 per cent by deployment and governance. This allocation seems counterintuitive—most organisations expect modelling to dominate—but data is where leverage occurs. An organisation that allocates only 20 per cent of budget to data preparation will face delays, accuracy shortfalls, and governance failures. The eight-week timeline is achievable only with front-loaded investment in problem definition and data audit.
For a mid-market organisation budgeting £180–320k for an AI MVP, typical resource allocation is: (1) one senior data scientist (lead, weeks 1–8); (2) one data engineer (data extraction and infrastructure, weeks 1–8); (3) one domain expert from the business (problem definition and validation, weeks 1–2 intensive, weeks 3–8 as-needed); (4) support from a data governance specialist or compliance officer (weeks 2–4 and 7–8). This is a lean team, not a large project. The small team size forces discipline: you cannot afford to explore tangential questions or build unnecessary infrastructure. Every decision must be purposeful.
Cost scales with problem complexity and data accessibility. A pilot using structured, well-organised internal build versus buy decision framework for AI data from a single system (e.g., customer churn prediction using a mature CRM) may cost £180k and consume 12 person-weeks of effort. A pilot requiring integration across multiple data silos, extensive feature engineering, and regulatory compliance (e.g., credit-risk assessment) may cost £320k and consume 20 person-weeks. The eight-week calendar timeline is achievable in both cases, but resource intensity varies. A sponsor should budget for the higher estimate and treat lower-cost outcomes as pleasant surprises, not plan on the lower estimate and face mid-project budget overruns.
Failure Pattern 1: Loose Problem Definition. Projects begin with a vague objective ("improve operations with AI") and no explicit success metrics. Weeks later, the team has built a model that no one knows how to use. Structured methodology avoids this: phase one mandates a precise, measurable problem definition and explicit sponsor sign-off. If the problem is too vague, that becomes apparent in week one, not week six.
Failure Pattern 2: Underestimated Data Preparation. Teams begin modelling with raw data, discover data quality issues midway through, and face project delays. Structured methodology reserves 40 per cent of budget for phases 1–2 (data audit). Data quality issues surface early, when remediation is cheap. If issues are severe, the team can pivot in week three; if the team has already committed to modelling, discovering the same issues in week five costs a month of rework.
Failure Pattern 3: Unachievable Accuracy Targets. Organisations define success metrics without understanding data constraints. "We need 95 per cent accuracy" is declared, then the team discovers the data can support only 78 per cent. Structured methodology includes explicit accuracy forecasting in phase two; if the forecast falls short of the target, the mismatch surfaces in week three, when options exist (pivot the problem, adjust the metric, acquire data). Discovering this mismatch in week six leaves no options.
Failure Pattern 4: Governance & Bias Surprises Late. Models are deployed, then regulators or customers raise fairness and governance concerns. Structured methodology makes bias and fairness assessment explicit in phases 2 and 3; issues surface early and can be addressed during modelling. Late-stage governance surprises are prevented.
Failure Pattern 5: Production Deployment Treated as Trivial. "We have a validated model; let us turn it on in production" is the assumption. Structured methodology separates MVP validation (phase 4 sandbox deployment) from production deployment (separate project). Sandbox deployment enables stakeholder review and risk mitigation; moving to production requires change management, monitoring validation, and stakeholder approval. This separation eliminates the "deployed and broke" scenario where a model is enabled in production without adequate governance, monitoring causes silent failures, and the organisation loses trust in AI.
The eight-week AI MVP framework is not faster execution of traditional software practices; it is a fundamentally different methodology for AI system development. It acknowledges that AI outcomes are data-dependent, that accuracy forecasting is essential before committing to modelling, and that governance is integral, not bolt-on. The four phases—problem definition, data audit, model development, and sandbox deployment—force hard questions early and prevent the categorical mismatches that cause the 72 per cent failure rate.
For organisations considering an AI pilot: (1) insist on rigorous problem definition with measurable success metrics and explicit ROI thresholds; (2) allocate 40 per cent of budget and effort to data preparation and audit, not modelling; (3) conduct formal accuracy forecasting before commencing development; (4) treat fairness and governance as first-class concerns, not afterthoughts; (5) plan for sandbox deployment and stakeholder review as mandatory gates; (6) separate MVP validation from production deployment. These disciplines are not bureaucracy. They are the difference between the 13 per cent of AI projects that succeed and the 87 per cent that fail.
The investment is material—£180–320k, eight weeks, and 12–20 person-weeks of effort. The return is clarity: organisations that follow this methodology know, with high confidence, whether an AI system can deliver business value in their context. They deploy with governance and monitoring in place, not as an afterthought. They avoid the pilot purgatory that claims 38 per cent of AI projects. In the current AI landscape, where pilot enthusiasm often exceeds pilot discipline, structured methodology is the competitive advantage.
For more guidance on AI implementation, read our AI transformation playbook, explore our guide to AI for business, or contact Helium42 to discuss your organisation's AI readiness and pilot strategy.

For UK operations and IT teams, the pressure is mounting. Teams juggle alert fatigue (75% of IT teams experience this monthly), tool sprawl (100–300...

AI for Supply Chain and Procurement: How UK Businesses Are Optimising Operations Artificial intelligence is reshaping how UK businesses forecast...

Artificial Intelligence is reshaping how UK real estate professionals operate. From predictive property valuations to compliance-driven tenant...